Opening the LLM pipeline
My notes on a great tutorial at NeurIPS 2024 on how to build a Large Language Model, with many practical tips.
3rd January 2025
This post summarizes a fanstic tutorial about building LLM, titled “Opening the Language Model Pipeline: A Tutorial on Data Preparation, Model Training, and Adaptation” (slides). It was presented at NeurIPS 2024, by Kyle Lo, Akshita Bhagia and Nathan Lambert, all from the Allen Institute for AI. I think it could be useful to share some of the main ideas.
The process to build a Large Language Model is very involved, and the authors went through it end to end, providing many details and practical knowledge: starting with the data preparation, continuing wiht model training (also called pre-training), and adaptation (or post-training). Here I summarize the main takeaways from each part, with some additional notes added.
Data preparation
Data preparation mainly means data acquisition, data transformation (deduplication, quality control, etc) and data evaluation.
Data acquisition
To acquire data, crawling is common. However, it’s becoming harder to crawl data. Many websites are opting out or implementing anti crawlers protection, as shown in the figure below. Note that this will create a barrier to enter for new players. As Kyle Lo said: we are not running out of data, we are running out of open data.
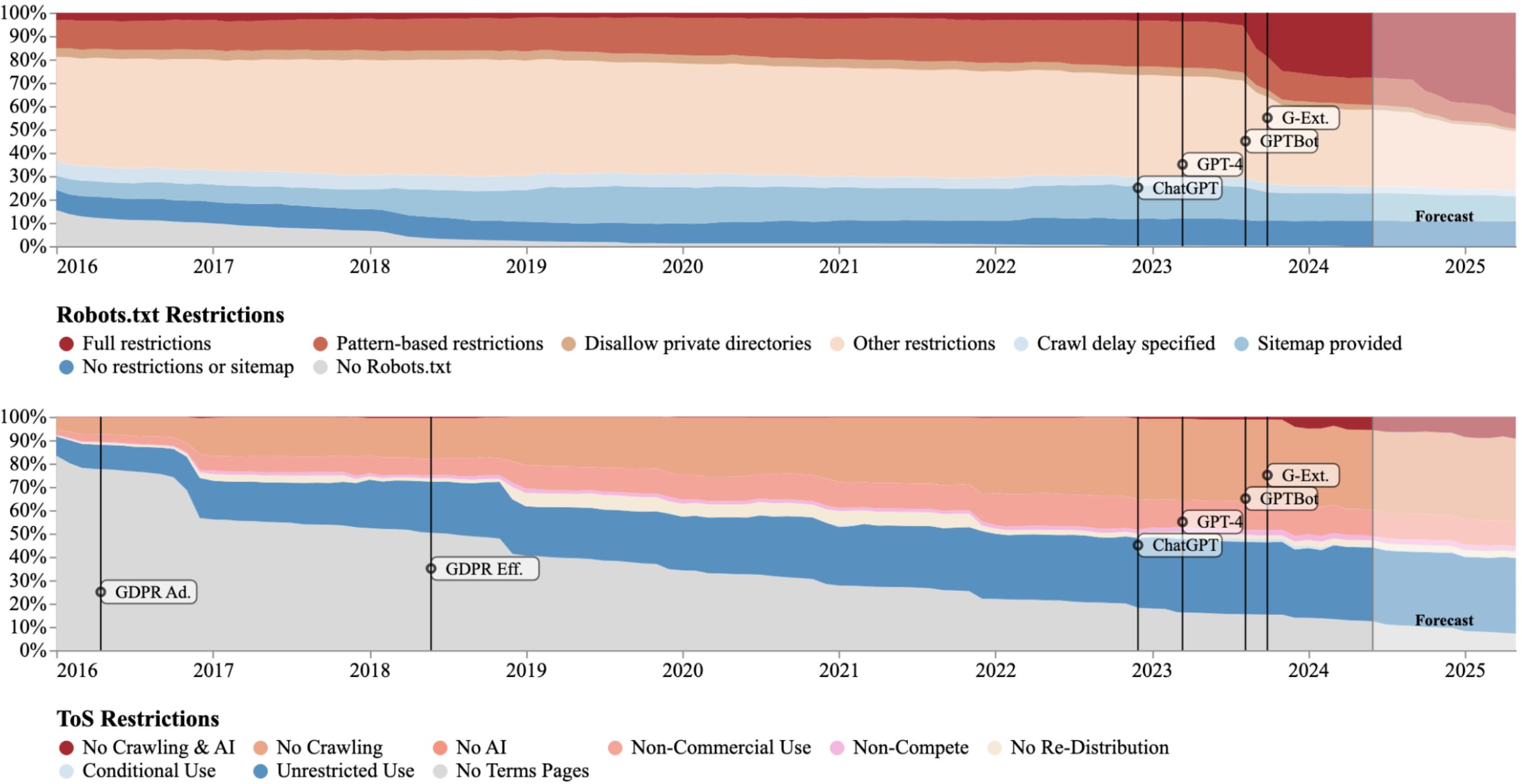
Crawling data from websites implies, for many of them, understanding the JavaScript logic, which in many cases is unique to the website. This can be challenging because each website may use different frameworks or obfuscation techniques, making it necessary to decipher custom implementations. For example, a site might load data dynamically through complex API calls embedded in asynchronous scripts, requiring tailored solutions for successful extraction. It also requires to parse the data from all the HTML, which is not easy. For PDF’s or scanned documents is also difficult, as many tools are not able to parse the data correctly.
Data transformation
That mostly means language filtering, deduplication, removing sensitive content (including private content) and ensuring a desired quality. In reality, it’s a classification problem, and can be done using machine learning with small classifiers. They recommend the library fastText, which is quite efficient (and used across the industry), although more involved classifiers can be used.
They also shared the amount of data that remains once the data is filtered for quality and deduplication: reductions are usually of the order of 65 times.
Filtering for quality can be, in some cases, problematics, as one can be undesiringly removing specific themes which are usually classified as lower quality, e.g. high school related content.
It is also quite difficult to remove personal data, as it was highlighted by Subramani et al (2023), where they showed that accuracies with simple Regex or tools like Presidio can be quite low.
Data evaluation
Finally, data must be evaluated by training models and running benchmarks, such as MMLU, HumanEval, GSM8K… The evaluation should be done systematically to each group of data, ideally starting with a smaller and cheaper mode. In general it is a very involved process with many nuances, like what is the best model size, measuring the effect of your data filtering, etc
A new trend: data curriculum
Some interesting new trend: “data curriculum”, which consists of, after training the model with trillions of tokens (high quantity, less quality), at the end of it one switches data to either very high quality sources, specific instructions or synthetic data.
Model training (or pre-training)
Pre-training, the process where you train a LLM on next token prediction with a large amount of text, is currently mostly done with a Transformer architecture, accepting many different configurations that are successful, including many attention mechanisms (e.g. multi head, grouped-query or multi-query). See image below, how different configurations of the hyperparameters (marked in red) can lead to successful models.
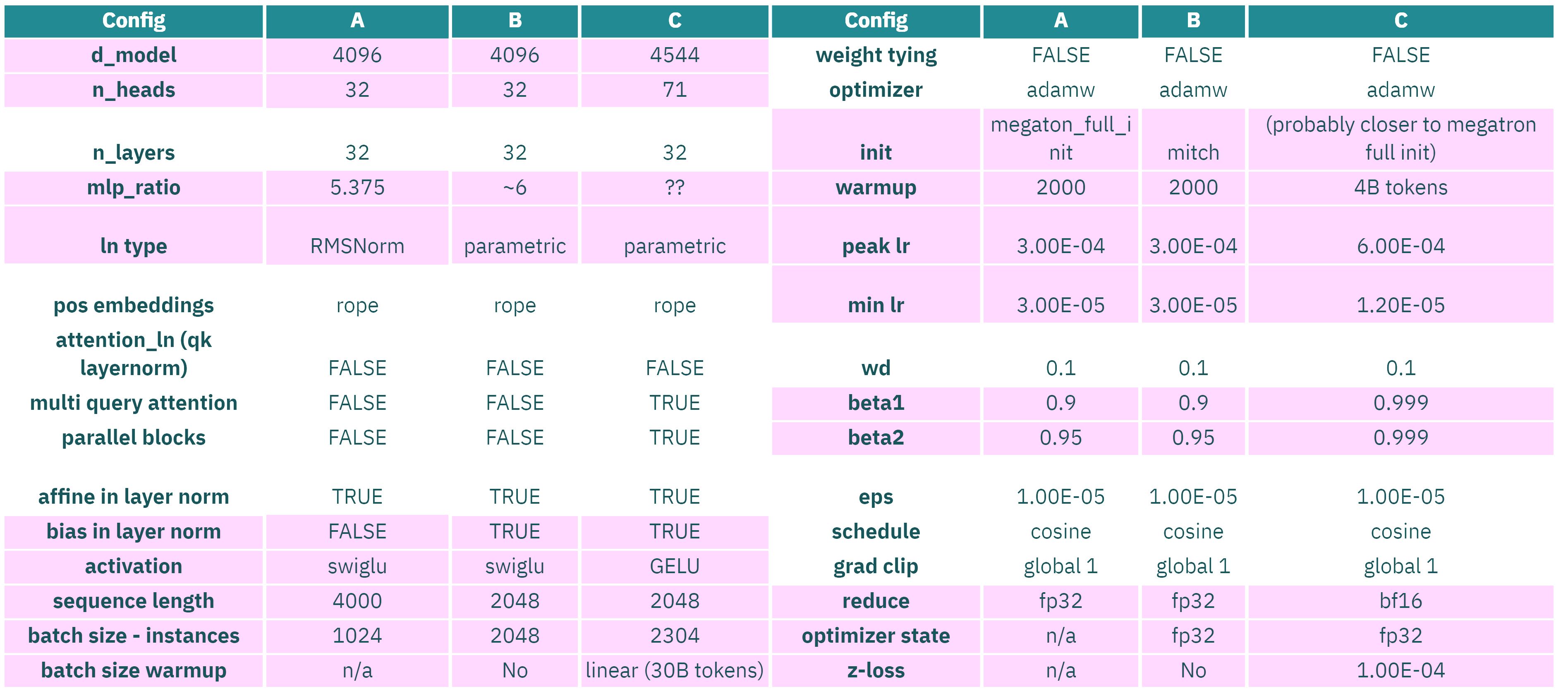
In terms of scale the approximate good scaling law given by the Chinchilla paper (compute budget approximately 6 times the number of parameters by data tokens, and data tokens approx 20 times the number of parameters), although in practice everybody keeps training further.
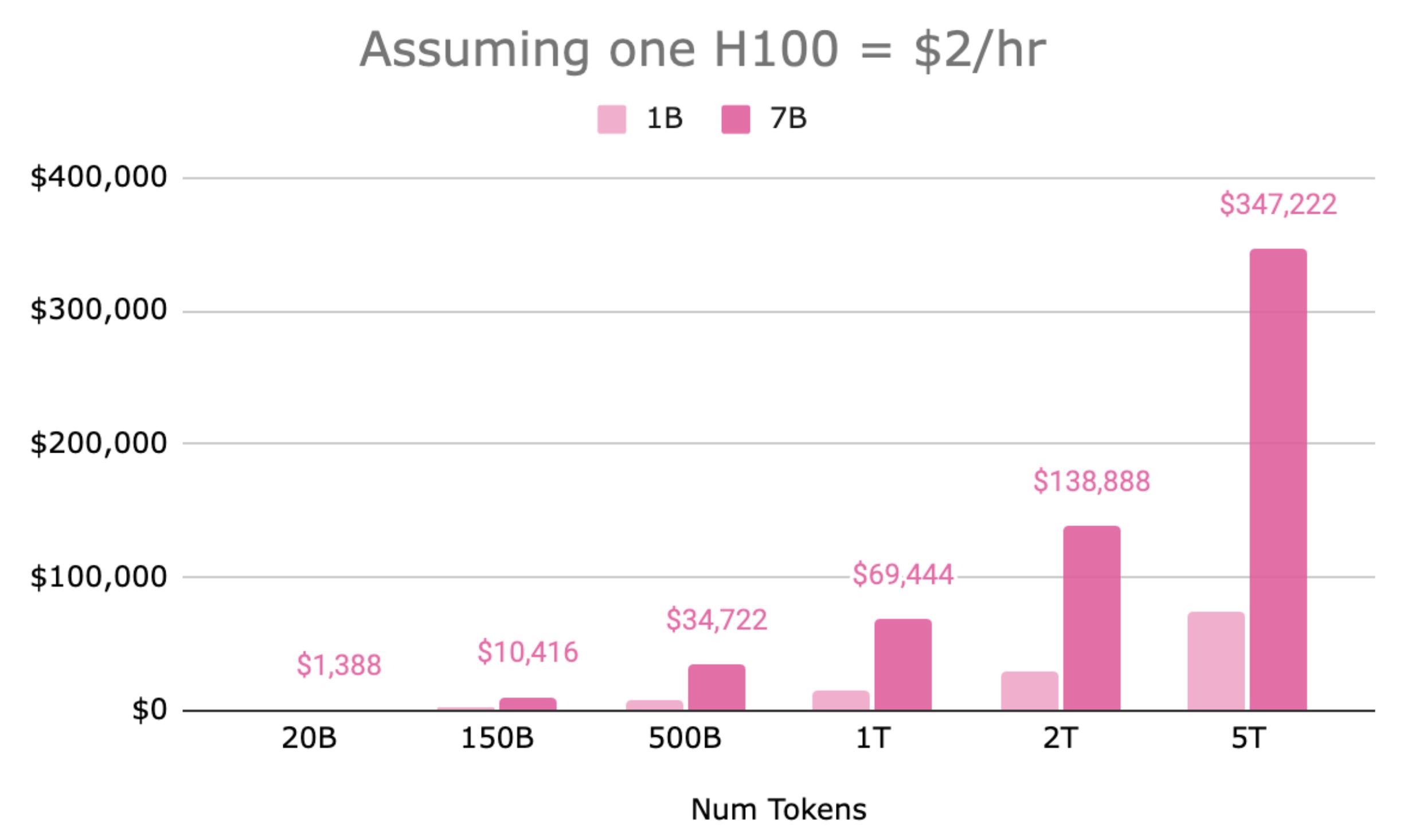
In terms of costs, the pre-training can be very expensive, as it is very intensive in computational resources. See for example the table below, by the authors of the tutorials: a 7b parameter model and 150B tokens (just above the Chinchilla paper budget), will cost approx $10k.
Common positional embeddings today are rotary positional embeddings (RoPE) and the SwiGLU activation, which, unlike ReLU activation, is smooth (differentiable) at zero.
Problems with loss function convergence
When the loss function spikes punctually, look at your data, probably is a low quality batch that needs to be filtered.
When the loss function starts spiking and diverging, one needs to ensure that the scale of activations and gradients remain roughly the same, and they should scale with model width. Better to use normal initialization and RMSNorm, QK-Norm and change the order of the layer norm. Finally, ensure that the token embedding does not become too small (no weight decay).
Run experiments with smaller models first, to find optimal parameters, decide on data ablations.
Additional tips for pre-training
Learning rate annealing also helped. Increase first with the first 10B tokens (to 3e-4) then reduce with cosine decay to 5e-5 for the following trillions of tokens and finally reduce to 0 in the last 50B tokens (e.g. with curriculum training).
Use efficient architectures such as Mixture of Experts.
In terms of distributing the training across GPU’s, the recommendation is to use FSDP. Here there is an excellent tutorial. One needs to ensure that the global batch size is not too large.
Use flash attention algorithm as is faster and more memory efficient. Try to keep your code simple, before using torch.compile.
With large training jobs it’s important to manually do garbage collection at the same time in all processes, as otherwise you can have stalls.
Adaptation (or post-training)
The output of the pre-training is not ready for use, as it is just predicting the next token. The model needs to be adapted to the specific task at hand: this is the alignment problem: i.e. how we align the model behavior with the human preferences (or the specific task).
The first step for adaptation is to have some target tasks (e.g. math, or writting code), with some meaningful evaluation, i.e. some specific benchmarks to evaluate. Then one needs to collect (or build) prompts that represent the task.
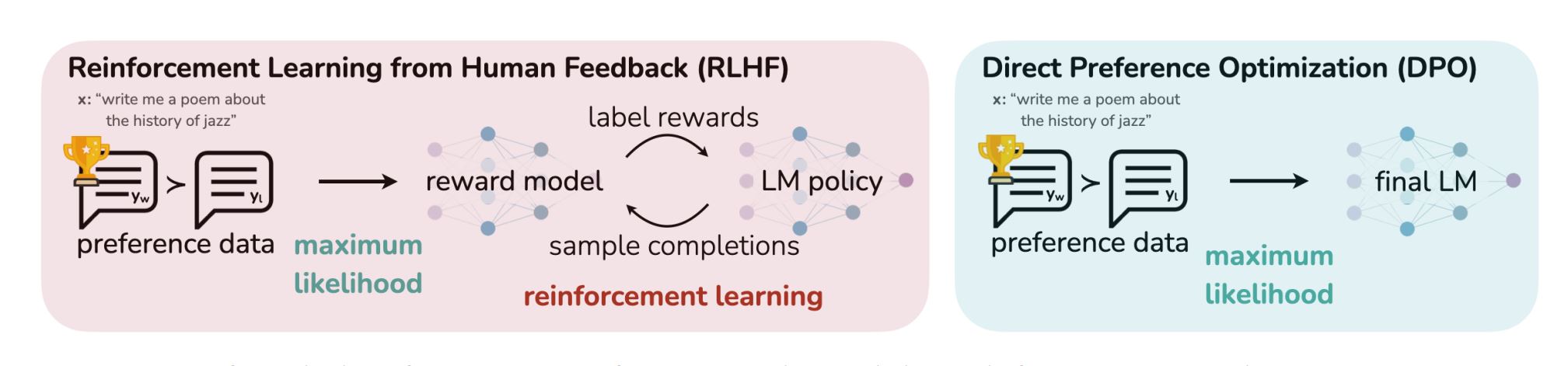
Currently, in many open source LLMs, different process from Reinforcement Learning from Human Feedback (RLHF), created by OpenAI, are used. In reality one can combine them, as we will see below.Some of these methods are:
- Direct Preference Optimization (DPO), much simpler with similar performance. It does not need a reward model (like RLHF), and requires only to optimize a modified version of a simple binary cross entropy objective. It is used in the Llama 3 model.
-
Supervise Fine Tuning (SFT) is a method that uses a supervised fine-tuning approach, where the model is fine-tuned on a small labeled dataset. It is used in the MM1 model from Apple.
-
Reinforcement Learning with Verifiable Rewards (RLVR) is a quite simple but effective method coined by the authors, where they replace RLHF by a scoring function that offers positive rewards if the answer is correct. Only applicable (for now) in verifiable rewards, such as math problems with known answers.
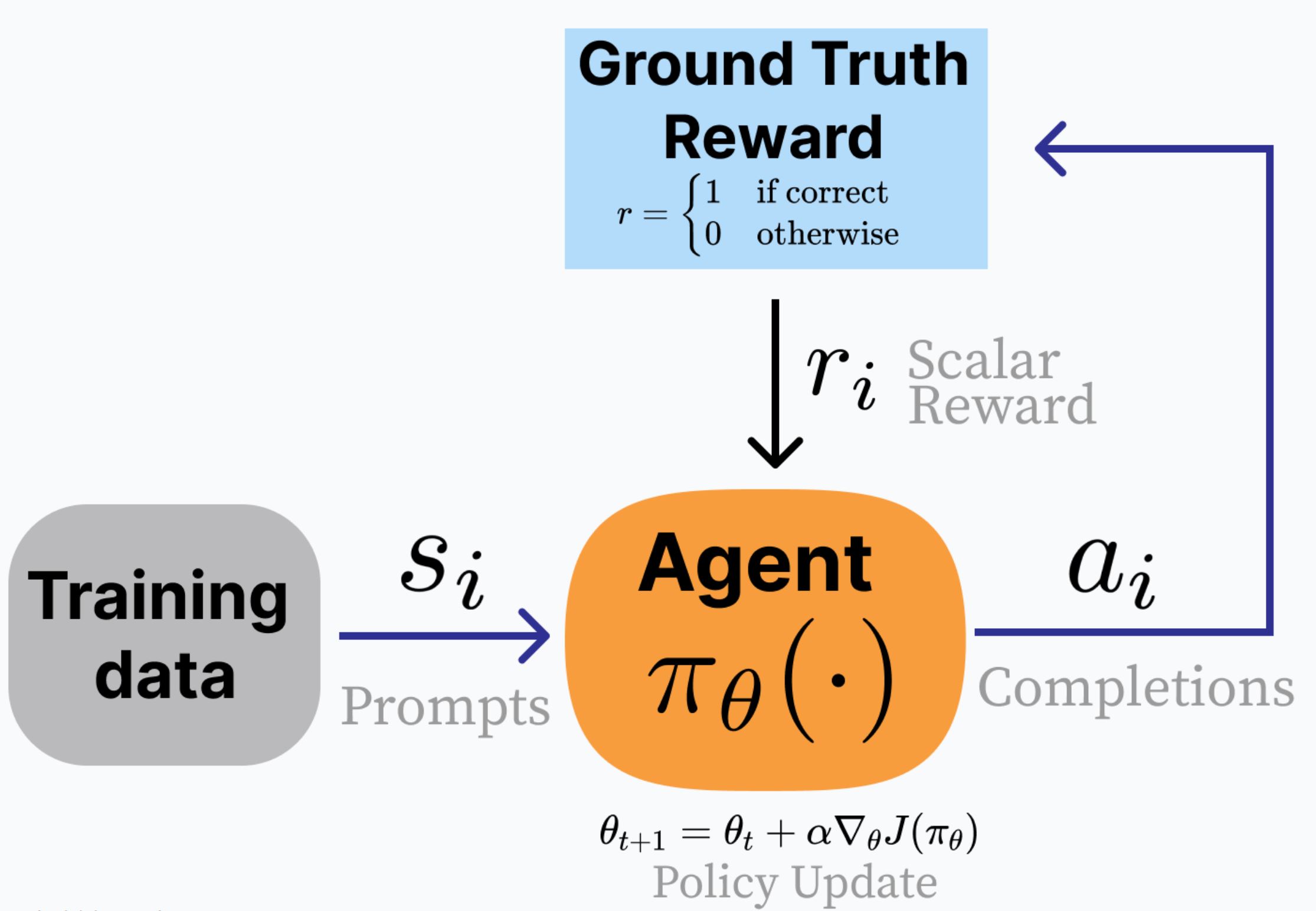
In terms of combining them, the authors of the tutorial suggest to start with SFT (e.g. ~1 million prompts), continue with DPO (another ~1 million prompts), and finally use Reinforcement Learning (~10k-100k prompts).
Supervised Fine Tuning
With SFT you can get ~80% of performance gain in many tasks.
Is used to adapt the pre-trained to specific styles of input, such as chat interactions, and can include system prompts, multi turn dialogues…
A lot of data on this category has been created syntehtically by using LLMs to generate variations of human created prompts.
Usually one start with mixing the existing datasets, evaluating with benchmarks, and on these benchmarks that are lagging, create new data (they usesd PersonaHub).
Preference Optimization (DPO)
Aligning to human preferences make the model stronger (e.g. ChatBotArena), allowing to control style.
Preference optimization takes a prompt with a chosen and a rejected completion (by a human), and assumes that the probability of the chosen completion should be higher than the rejected one.
Surprisingly low learning rates (~5E-7) are standard use. With a 70B parameter model the people from the Allen Institute were able to surpass GPT-4 in various benchmarks.
Reinforcement Learning
Although more complex, it allows to normally get ~1% better performance. One can start with synthetic data (LLM-as-a-judge), that has low noise and high bias and then move to human data, with high noise but low bias.
The leading synthetic preference data method is UltraFeedback, where instructions are sampled from a large pool of models and GPT-4 is used to annotate preferences.
They used the RLVR method, where there is no reward function but just a scoring function that offers positive rewards if the answer is correct. This is for now limited to math and precise instructions.
Conclusions
The talk reminded me of other recent articles which describe the LLM building process (or at least provide some details), such as the very insightful paper from Apple about their MM1 model, or the one from Meta on Llama 3.1.
The folks from the Allen Institute were very generous in sharing their knowledge, as I think many tips from their practical knowledge may be useful. They also shared this repository with many open source models and resources.
I hope the video is shared soon in the tutorial page.
Edit: Nathan Lambert tells me that he re-recorded the last part of the tutorial, you can enjoy it here: The state of post-training in 2025.